怎么优化 PPPoE 的 MTU
/ 约 1226 字
/ 预计阅读 3 分钟
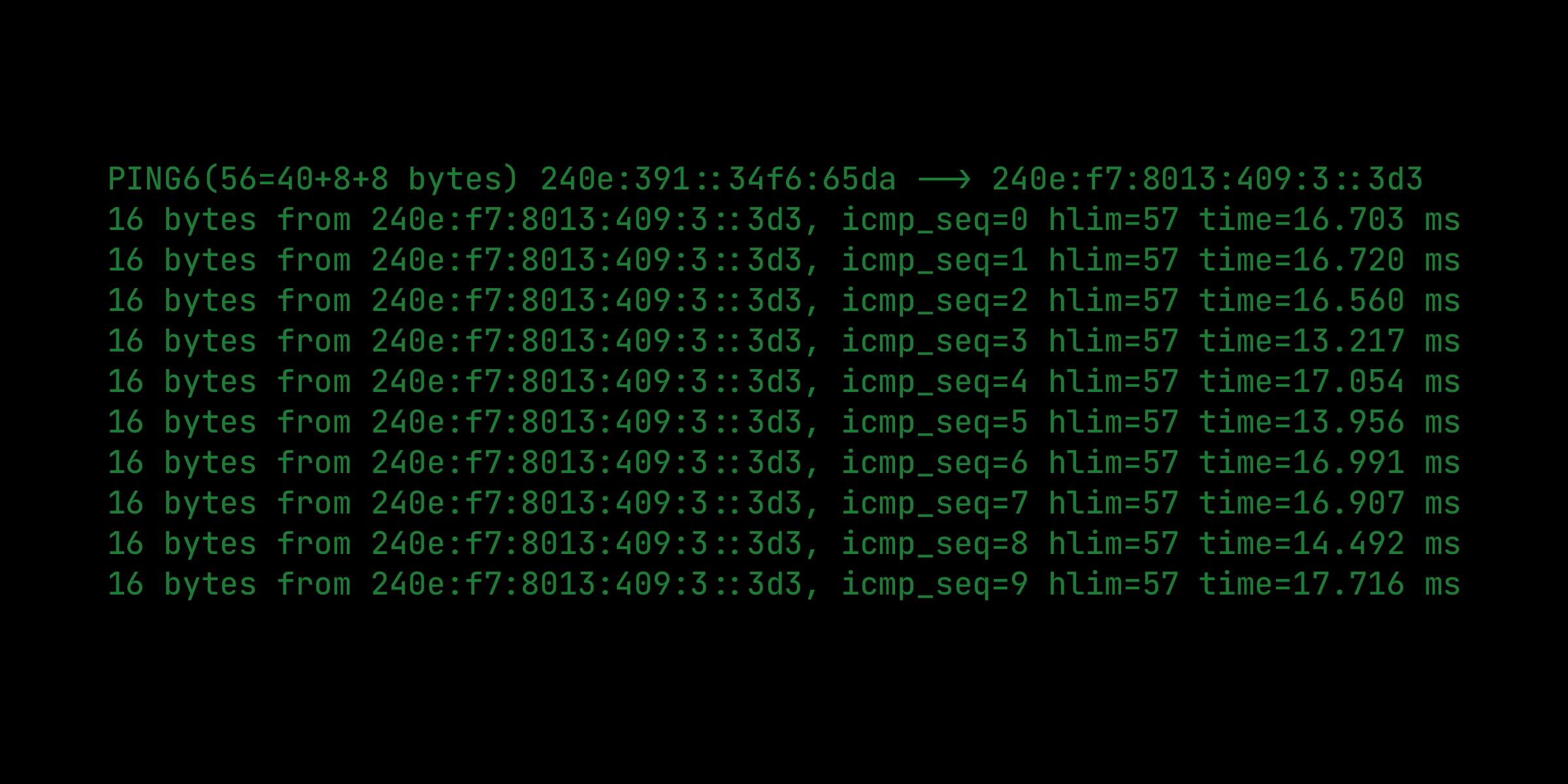
通过 PPPoE 方式拨号上网的用户(包括常见的光猫),如果路由器的 MTU 设置不正确,可能会导致网速下降或者无法上网。 关于 MTU # MTU(maximum transmission unit) 其实属于二层的一个概念,它的目的是限定「MAC 帧中数据部分(payload)」的大小
使用 acme.sh 签发免费的通配符 SSL 证书
/ 约 1403 字
/ 预计阅读 3 分钟

网站启用 HTTPS 可以应对运营商的「HTTP 劫持」,避免被插入广告。大多数情况,使用免费的「SSL 证书」就足够了。 推荐的 CA 及签发工具 # ZeroSSL、Let’s Encrypt 是两个常见的 CA(证书授权机构)。
怎么清空 git 提交记录
/ 约 263 字
/ 预计阅读 1 分钟

对于 git,如果你想删除所有提交记录但保留所有的文件,那么可以按照以下步骤操作。 请勿直接删除 .git 文件夹,这会导致你的 git 仓库出现问题。 1. 创建孤立分支 # git checkout --orphan new_branch 此操作会创建一个没有父分支的新分支, 名为 new_branch, 并切